Chris Lamb: Favourite books of 2022: Non-fiction
 In my three most recent posts, I went over the memoirs and biographies, classics and fiction books that I enjoyed the most in 2022. But in the last of my book-related posts for 2022, I'll be going over my favourite works of non-fiction.
Books that just missed the cut here include Adam Hochschild's King Leopold's Ghost (1998) on the role of Leopold II of Belgium in the Congo Free State, Johann Hari's Stolen Focus (2022) (a personal memoir on relating to how technology is increasingly fragmenting our attention), Amia Srinivasan's The Right to Sex (2021) (a misleadingly named set of philosophic essays on feminism), Dana Heller et al.'s The Selling of 9/11: How a National Tragedy Became a Commodity (2005), John Berger's mindbending Ways of Seeing (1972) and Louise Richardson's What Terrorists Want (2006).
In my three most recent posts, I went over the memoirs and biographies, classics and fiction books that I enjoyed the most in 2022. But in the last of my book-related posts for 2022, I'll be going over my favourite works of non-fiction.
Books that just missed the cut here include Adam Hochschild's King Leopold's Ghost (1998) on the role of Leopold II of Belgium in the Congo Free State, Johann Hari's Stolen Focus (2022) (a personal memoir on relating to how technology is increasingly fragmenting our attention), Amia Srinivasan's The Right to Sex (2021) (a misleadingly named set of philosophic essays on feminism), Dana Heller et al.'s The Selling of 9/11: How a National Tragedy Became a Commodity (2005), John Berger's mindbending Ways of Seeing (1972) and Louise Richardson's What Terrorists Want (2006).
The Great War and Modern Memory (1975)
Wartime: Understanding and Behavior in the Second World War (1989)
Paul Fussell
Rather than describe the battles, weapons, geopolitics or big personalities of the two World Wars, Paul Fussell's The Great War and Modern Memory & Wartime are focused instead on how the two wars have been remembered by their everyday participants. Drawing on the memoirs and memories of soldiers and civilians along with a brief comparison with the actual events that shaped them, Fussell's two books are a compassionate, insightful and moving piece of analysis.
Fussell primarily sets himself against the admixture of nostalgia and trauma that obscures the origins and unimaginable experience of participating in these wars; two wars that were, in his view, a "perceptual and rhetorical scandal from which total recovery is unlikely." He takes particular aim at the dishonesty of hindsight:
For the past fifty years, the Allied war has been sanitised and romanticised almost beyond recognition by the sentimental, the loony patriotic, the ignorant and the bloodthirsty. I have tried to balance the scales. [And] in unbombed America especially, the meaning of the war [seems] inaccessible.The author does not engage in any of the customary rose-tinted view of war, yet he remains understanding and compassionate towards those who try to locate a reason within what was quite often senseless barbarism. If anything, his despondency and pessimism about the Second World War (the war that Fussell himself fought in) shines through quite acutely, and this is especially the case in what he chooses to quote from others:
"It was common [ ] throughout the [Okinawa] campaign for replacements to get hit before we even knew their names. They came up confused, frightened, and hopeful, got wounded or killed, and went right back to the rear on the route by which they had come, shocked, bleeding, or stiff. They were forlorn figures coming up to the meat grinder and going right back out of it like homeless waifs, unknown and faceless to us, like unread books on a shelf."It would take a rather heartless reader to fail to be sobered by this final simile, and an even colder one to view Fussell's citation of such an emotive anecdote to be manipulative. Still, stories and cruel ironies like this one infuse this often-angry book, but it is not without astute and shrewd analysis as well, especially on the many qualitative differences between the two conflicts that simply cannot be captured by facts and figures alone. For example:
A measure of the psychological distance of the Second [World] War from the First is the rarity, in 1914 1918, of drinking and drunkenness poems.Indeed so. In fact, what makes Fussell's project so compelling and perhaps even unique is that he uses these non-quantitive measures to try and take stock of what happened. After all, this was a war conducted by humans, not the abstract school of statistics. And what is the value of a list of armaments destroyed by such-and-such a regiment when compared with truly consequential insights into both how the war affected, say, the psychology of postwar literature ("Prolonged trench warfare, whether enacted or remembered, fosters paranoid melodrama, which I take to be a primary mode in modern writing."), the specific words adopted by combatants ("It is a truism of military propaganda that monosyllabic enemies are easier to despise than others") as well as the very grammar of interaction:
The Field Service Post Card [in WW1] has the honour of being the first widespread exemplary of that kind of document which uniquely characterises the modern world: the "Form". [And] as the first widely known example of dehumanised, automated communication, the post card popularised a mode of rhetoric indispensable to the conduct of later wars fought by great faceless conscripted armies.And this wouldn't be a book review without argument-ending observations that:
Indicative of the German wartime conception [of victory] would be Hitler and Speer's elaborate plans for the ultimate reconstruction of Berlin, which made no provision for a library.Our myths about the two world wars possess an undisputed power, in part because they contain an essential truth the atrocities committed by Germany and its allies were not merely extreme or revolting, but their full dimensions (embodied in the Holocaust and the Holodomor) remain essentially inaccessible within our current ideological framework. Yet the two wars are better understood as an abyss in which we were all dragged into the depths of moral depravity, rather than a battle pitched by the forces of light against the forces of darkness. Fussell is one of the few observers that can truly accept and understand this truth and is still able to speak to us cogently on the topic from the vantage point of experience. The Second World War which looms so large in our contemporary understanding of the modern world (see below) may have been necessary and unavoidable, but Fussell convinces his reader that it was morally complicated "beyond the power of any literary or philosophic analysis to suggest," and that the only way to maintain a na ve belief in the myth that these wars were a Manichaean fight between good and evil is to overlook reality. There are many texts on the two World Wars that can either stir the intellect or move the emotions, but Fussell's two books do both. A uniquely perceptive and intelligent commentary; outstanding.
Longitude (1995) Dava Sobel Since Man first decided to sail the oceans, knowing one's location has always been critical. Yet doing so reliably used to be a serious problem if you didn't know where you were, you are far more likely to die and/or lose your valuable cargo. But whilst finding one's latitude (ie. your north south position) had effectively been solved by the beginning of the 17th century, finding one's (east west) longitude was far from trustworthy in comparison. This book first published in 1995 is therefore something of an anachronism. As in, we readily use the GPS facilities of our phones today without hesitation, so we find it difficult to imagine a reality in which knowing something fundamental like your own location is essentially unthinkable. It became clear in the 18th century, though, that in order to accurately determine one's longitude, what you actually needed was an accurate clock. In Longitude, therefore, we read of the remarkable story of John Harrison and his quest to create a timepiece that would not only keep time during a long sea voyage but would survive the rough ocean conditions as well. Self-educated and a carpenter by trade, Harrison made a number of important breakthroughs in keeping accurate time at sea, and Longitude describes his novel breakthroughs in a way that is both engaging and without talking down to the reader. Still, this book covers much more than that, including the development of accurate longitude going hand-in-hand with advancements in cartography as well as in scientific experiments to determine the speed of light: experiments that led to the formulation of quantum mechanics. It also outlines the work being done by Harrison's competitors. 'Competitors' is indeed the correct word here, as Parliament offered a huge prize to whoever could create such a device, and the ramifications of this tremendous financial incentive are an essential part of this story. For the most part, though, Longitude sticks to the story of Harrison and his evolving obsession with his creating the perfect timepiece. Indeed, one reason that Longitude is so resonant with readers is that many of the tropes of the archetypical 'English inventor' are embedded within Harrison himself. That is to say, here is a self-made man pushing against the establishment of the time, with his groundbreaking ideas being underappreciated in his life, or dishonestly purloined by his intellectual inferiors. At the level of allegory, then, I am minded to interpret this portrait of Harrison as a symbolic distillation of postwar Britain a nation acutely embarrassed by the loss of the Empire that is now repositioning itself as a resourceful but plucky underdog; a country that, with a combination of the brains of boffins and a healthy dose of charisma and PR, can still keep up with the big boys. (It is this same search for postimperial meaning I find in the fiction of John le Carr , and, far more famously, in the James Bond franchise.) All of this is left to the reader, of course, as what makes Longitute singularly compelling is its gentle manner and tone. Indeed, at times it was as if the doyenne of sci-fi Ursula K. LeGuin had a sideline in popular non-fiction. I realise it's a mark of critical distinction to downgrade the importance of popular science in favour of erudite academic texts, but Latitude is ample evidence that so-called 'pop' science need not be patronising or reductive at all.
Closed Chambers: The Rise, Fall, and Future of the Modern Supreme Court (1998) Edward Lazarus After the landmark decision by the U.S. Supreme Court in *Dobbs v. Jackson Women's Health Organization that ended the Constitutional right to abortion conferred by Roe v Wade, I prioritised a few books in the queue about the judicial branch of the United States. One of these books was Closed Chambers, which attempts to assay, according to its subtitle, "The Rise, Fall and Future of the Modern Supreme Court". This book is not merely simply a learned guide to the history and functioning of the Court (although it is completely creditable in this respect); it's actually an 'insider' view of the workings of the institution as Lazurus was a clerk for Justice Harry Blackmun during the October term of 1988. Lazarus has therefore combined his experience as a clerk and his personal reflections (along with a substantial body of subsequent research) in order to communicate the collapse in comity between the Justices. Part of this book is therefore a pure history of the Court, detailing its important nineteenth-century judgements (such as Dred Scott which ruled that the Constitution did not consider Blacks to be citizens; and Plessy v. Ferguson which failed to find protection in the Constitution against racial segregation laws), as well as many twentieth-century cases that touch on the rather technical principle of substantive due process. Other layers of Lazurus' book are explicitly opinionated, however, and they capture the author's assessment of the Court's actions in the past and present [1998] day. Given the role in which he served at the Court, particular attention is given by Lazarus to the function of its clerks. These are revealed as being far more than the mere amanuenses they were hitherto believed to be. Indeed, the book is potentially unique in its the claim that the clerks have played a pivotal role in the deliberations, machinations and eventual rulings of the Court. By implication, then, the clerks have plaedy a crucial role in the internal controversies that surround many of the high-profile Supreme Court decisions decisions that, to the outsider at least, are presented as disinterested interpretations of Constitution of the United States. This is of especial importance given that, to Lazarus, "for all the attention we now pay to it, the Court remains shrouded in confusion and misunderstanding." Throughout his book, Lazarus complicates the commonplace view that the Court is divided into two simple right vs. left political factions, and instead documents an ever-evolving series of loosely held but strongly felt series of cabals, quid pro quo exchanges, outright equivocation and pure personal prejudices. (The age and concomitant illnesses of the Justices also appears to have a not insignificant effect on the Court's rulings as well.) In other words, Closed Chambers is not a book that will be read in a typical civics class in America, and the only time the book resorts to the customary breathless rhetoric about the US federal government is in its opening chapter:
The Court itself, a Greek-style temple commanding the crest of Capitol Hill, loomed above them in the dim light of the storm. Set atop a broad marble plaza and thirty-six steps, the Court stands in splendid isolation appropriate to its place at the pinnacle of the national judiciary, one of the three independent and "coequal" branches of American government. Once dubbed the Ivory Tower by architecture critics, the Court has a Corinthian colonnade and massive twenty-foot-high bronze doors that guard the single most powerful judicial institution in the Western world. Lights still shone in several offices to the right of the Court's entrance, and [ ]Et cetera, et cetera. But, of course, this encomium to the inherent 'nobility' of the Supreme Court is quickly revealed to be a narrative foil, as Lazarus soon razes this dangerously na ve conception to the ground:
[The] institution is [now] broken into unyielding factions that have largely given up on a meaningful exchange of their respective views or, for that matter, a meaningful explication or defense of their own views. It is of Justices who in many important cases resort to transparently deceitful and hypocritical arguments and factual distortions as they discard judicial philosophy and consistent interpretation in favor of bottom-line results. This is a Court so badly splintered, yet so intent on lawmaking, that shifting 5-4 majorities, or even mere pluralities, rewrite whole swaths of constitutional law on the authority of a single, often idiosyncratic vote. It is also a Court where Justices yield great and excessive power to immature, ideologically driven clerks, who in turn use that power to manipulate their bosses and the institution they ostensibly serve.Lazurus does not put forward a single, overarching thesis, but in the final chapters, he does suggest a potential future for the Court:
In the short run, the cure for what ails the Court lies solely with the Justices. It is their duty, under the shield of life tenure, to recognize the pathologies affecting their work and to restore the vitality of American constitutionalism. Ultimately, though, the long-term health of the Court depends on our own resolve on whom [we] select to join that institution.Back in 1998, Lazurus might have had room for this qualified optimism. But from the vantage point of 2022, it appears that the "resolve" of the United States citizenry was not muscular enough to meet his challenge. After all, Lazurus was writing before Bush v. Gore in 2000, which arrogated to the judicial branch the ability to decide a presidential election; the disillusionment of Barack Obama's failure to nominate a replacement for Scalia; and many other missteps in the Court as well. All of which have now been compounded by the Trump administration's appointment of three Republican-friendly justices to the Court, including hypocritically appointing Justice Barrett a mere 38 days before the 2020 election. And, of course, the leaking and ruling in Dobbs v. Jackson, the true extent of which has not been yet. Not of a bit of this is Lazarus' fault, of course, but the Court's recent decisions (as well as the liberal hagiographies of 'RBG') most perforce affect one's reading of the concluding chapters. The other slight defect of Closed Chambers is that, whilst it often implies the importance of the federal and state courts within the judiciary, it only briefly positions the Supreme Court's decisions in relation to what was happening in the House, Senate and White House at the time. This seems to be increasingly relevant as time goes on: after all, it seems fairly clear even to this Brit that relying on an activist Supreme Court to enact progressive laws must be interpreted as a failure of the legislative branch to overcome the perennial problems of the filibuster, culture wars and partisan bickering. Nevertheless, Lazarus' book is in equal parts ambitious, opinionated, scholarly and dare I admit it? wonderfully gossipy. By juxtaposing history, memoir, and analysis, Closed Chambers combines an exacting evaluation of the Court's decisions with a lively portrait of the intellectual and emotional intensity that has grown within the Supreme Court's pseudo-monastic environment all while it struggles with the most impactful legal issues of the day. This book is an excellent and well-written achievement that will likely never be repeated, and a must-read for anyone interested in this ever-increasingly important branch of the US government.
Crashed: How a Decade of Financial Crises Changed the World (2018)
Shutdown: How Covid Shook the World's Economy (2021)
Adam Tooze
The economic historian Adam Tooze has often been labelled as an unlikely celebrity, but in the fourteen years since the global financial crisis of 2008, a growing audience has been looking for answers about the various failures of the modern economy. Tooze, a professor of history at New York's Columbia University, has written much that is penetrative and thought-provoking on this topic, and as a result, he has generated something of a cult following amongst economists, historians and the online left.
I actually read two Tooze books this year. The first, Crashed (2018), catalogues the scale of government intervention required to prop up global finance after the 2008 financial crisis, and it characterises the different ways that countries around the world failed to live up to the situation, such as doing far too little, or taking action far too late. The connections between the high-risk subprime loans, credit default swaps and the resulting liquidity crisis in the US in late 2008 is fairly well known today in part thanks to films such as Adam McKay's 2015 The Big Short and much improved economic literacy in media reportage. But Crashed makes the implicit claim that, whilst the specific and structural origins of the 2008 crisis are worth scrutinising in exacting detail, it is the reaction of states in the months and years after the crash that has been overlooked as a result.
After all, this is a reaction that has not only shaped a new economic order, it has created one that does not fit any conventional idea about the way the world 'ought' to be run. Tooze connects the original American banking crisis to the (multiple) European debt crises with a larger crisis of liberalism. Indeed, Tooze somehow manages to cover all these topics and more, weaving in Trump, Brexit and Russia's 2014 annexation of Crimea, as well as the evolving role of China in the post-2008 economic order.
Where Crashed focused on the constellation of consequences that followed the events of 2008, Shutdown is a clear and comprehensive account of the way the world responded to the economic impact of Covid-19. The figures are often jaw-dropping: soon after the disease spread around the world, 95% of the world's economies contracted simultaneously, and at one point, the global economy shrunk by approximately 20%. Tooze's keen and sobering analysis of what happened is made all the more remarkable by the fact that it came out whilst the pandemic was still unfolding. In fact, this leads quickly to one of the book's few flaws: by being published so quickly, Shutdown prematurely over-praises China's 'zero Covid' policy, and these remarks will make a reader today squirm in their chair. Still, despite the regularity of these references (after all, mentioning China is very useful when one is directly comparing economic figures in early 2021, for examples), these are actually minor blemishes on the book's overall thesis.
That is to say, Crashed is not merely a retelling of what happened in such-and-such a country during the pandemic; it offers in effect a prediction about what might be coming next. Whilst the economic responses to Covid averted what could easily have been another Great Depression (and thus showed it had learned some lessons from 2008), it had only done so by truly discarding the economic rule book. The by-product of inverting this set of written and unwritten conventions that have governed the world for the past 50 years, this 'Washington consensus' if you well, has yet to be fully felt.
Of course, there are many parallels between these two books by Tooze. Both the liquidity crisis outlined in Crashed and the economic response to Covid in Shutdown exposed the fact that one of the central tenets of the modern economy ie. that financial markets can be trusted to regulate themselves was entirely untrue, and likely was false from the very beginning. And whilst Adam Tooze does not offer a singular piercing insight (conveying a sense of rigorous mastery instead), he may as well be asking whether we're simply going to lurch along from one crisis to the next, relying on the technocrats in power to fix problems when everything blows up again. The answer may very well be yes.
Looking for the Good War: American Amnesia and the Violent Pursuit of Happiness (2021) Elizabeth D. Samet Elizabeth D. Samet's Looking for the Good War answers the following question what would be the result if you asked a professor of English to disentangle the complex mythology we have about WW2 in the context of the recent US exit of Afghanistan? Samet's book acts as a twenty-first-century update of a kind to Paul Fussell's two books (reviewed above), as well as a deeper meditation on the idea that each new war is seen through the lens of the previous one. Indeed, like The Great War and Modern Memory (1975) and Wartime (1989), Samet's book is a perceptive work of demystification, but whilst Fussell seems to have been inspired by his own traumatic war experience, Samet is not only informed by her teaching West Point military cadets but by the physical and ontological wars that have occurred during her own life as well. A more scholarly and dispassionate text is the result of Samet's relative distance from armed combat, but it doesn't mean Looking for the Good War lacks energy or inspiration. Samet shares John Adams' belief that no political project can entirely shed the innate corruptions of power and ambition and so it is crucial to analyse and re-analyse the role of WW2 in contemporary American life. She is surely correct that the Second World War has been universally elevated as a special, 'good' war. Even those with exceptionally giddy minds seem to treat WW2 as hallowed:
It is nevertheless telling that one of the few occasions to which Trump responded with any kind of restraint while he was in office was the 75th anniversary of D-Day in 2019.What is the source of this restraint, and what has nurtured its growth in the eight decades since WW2 began? Samet posits several reasons for this, including the fact that almost all of the media about the Second World War is not only suffused with symbolism and nostalgia but, less obviously, it has been made by people who have no experience of the events that they depict. Take Stephen Ambrose, author of Steven Spielberg's Band of Brothers miniseries: "I was 10 years old when the war ended," Samet quotes of Ambrose. "I thought the returning veterans were giants who had saved the world from barbarism. I still think so. I remain a hero worshiper." If Looking for the Good War has a primary thesis, then, it is that childhood hero worship is no basis for a system of government, let alone a crusading foreign policy. There is a straight line (to quote this book's subtitle) from the "American Amnesia" that obscures the reality of war to the "Violent Pursuit of Happiness." Samet's book doesn't merely just provide a modern appendix to Fussell's two works, however, as it adds further layers and dimensions he overlooked. For example, Samet provides some excellent insight on the role of Western, gangster and superhero movies, and she is especially good when looking at noir films as a kind of kaleidoscopic response to the Second World War:
Noir is a world ruled by bad decisions but also by bad timing. Chance, which plays such a pivotal role in war, bleeds into this world, too.Samet rightfully weaves the role of women into the narrative as well. Women in film noir are often celebrated as 'independent' and sassy, correctly reflecting their newly-found independence gained during WW2. But these 'liberated' roles are not exactly a ringing endorsement of this independence: the 'femme fatale' and the 'tart', etc., reflect a kind of conditional freedom permitted to women by a post-War culture which is still wedded to an outmoded honour culture. In effect, far from being novel and subversive, these roles for women actually underwrote the ambient cultural disapproval of women's presence in the workforce. Samet later connects this highly-conditional independence with the liberation of Afghan women, which:
is inarguably one of the more palatable outcomes of our invasion, and the protection of women's rights has been invoked on the right and the left as an argument for staying the course in Afghanistan. How easily consequence is becoming justification. How flattering it will be one day to reimagine it as original objective.Samet has ensured her book has a predominantly US angle as well, for she ends her book with a chapter on the pseudohistorical Lost Cause of the Civil War. The legacy of the Civil War is still visible in the physical phenomena of Confederate statues, but it also exists in deep-rooted racial injustice that has been shrouded in euphemism and other psychological devices for over 150 years. Samet believes that a key part of what drives the American mythology about the Second World War is the way in which it subconsciously cleanses the horrors of brother-on-brother murder that were seen in the Civil War. This is a book that is not only of interest to historians of the Second World War; it is a work for anyone who wishes to understand almost any American historical event, social issue, politician or movie that has appeared since the end of WW2. That is for better or worse everyone on earth.


 I m trying to replace my old OpenPGP key with a new one. The old key wasn t compromised or lost or anything
bad. Is still valid, but I plan to get rid of it soon. It was created in 2013.
The new key id fingerprint is:
I m trying to replace my old OpenPGP key with a new one. The old key wasn t compromised or lost or anything
bad. Is still valid, but I plan to get rid of it soon. It was created in 2013.
The new key id fingerprint is: 




 In June I travelled to see Nine Inch Nails perform two nights at the
In June I travelled to see Nine Inch Nails perform two nights at the 








 Being able to SSH into remote machines and do work there is great. Using hardware security tokens for 2FA is also great. But trying to use them both at the same time doesn't work super well, because if you hit a WebAuthn request on the remote machine it doesn't matter how much you mash your token - it's not going to work.
Being able to SSH into remote machines and do work there is great. Using hardware security tokens for 2FA is also great. But trying to use them both at the same time doesn't work super well, because if you hit a WebAuthn request on the remote machine it doesn't matter how much you mash your token - it's not going to work. More ICFP-inspired experiments using the
More ICFP-inspired experiments using the  Norman Ramsey shows a formula
Norman Ramsey shows a formula

 As promised, on this post I m going to explain how I ve configured this blog
using
As promised, on this post I m going to explain how I ve configured this blog
using 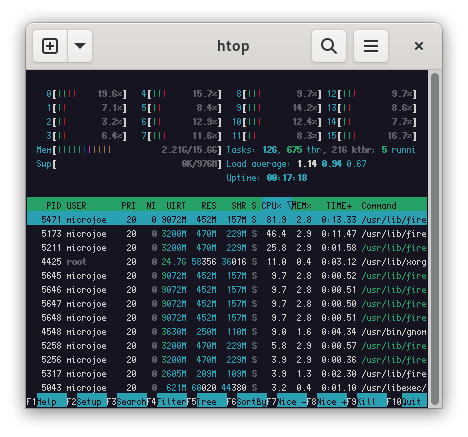 This means that I can
This means that I can  Checks out.
Checks out.
 Indeed, the GTK folks have managed to develop a similar solution named
Indeed, the GTK folks have managed to develop a similar solution named